背景:
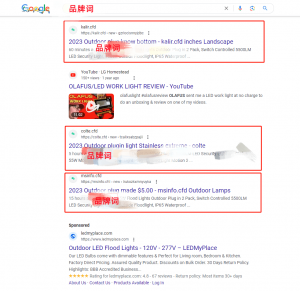
今天在搜索品牌词的时候,发现Google SERPs底部出现了垃圾内容,而这部分SERPs居然会显示我们的品牌词。如图1。
所以我的疑问是:
- 为什么这部分内容可以出现在SERPs中?
- 这些网站的内容中为什么会包含用户的搜索关键字?
- 通过什么技术实现?
- Google是否无法过滤掉这些垃圾内容?
调研开始:
- 这是存在SERPs中的3个网页,①https://msinfo.cfd/new/lrukozkxmnyuyka,②https://colte.cfd/new/tcalixsabzpajii,③https://kalir.cfd/new/gzrlocisnnyjdbc;
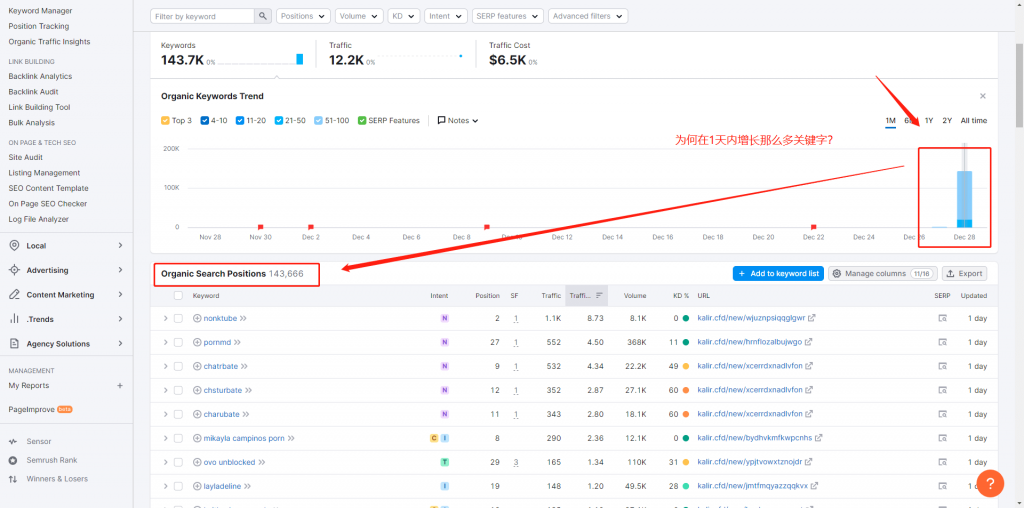
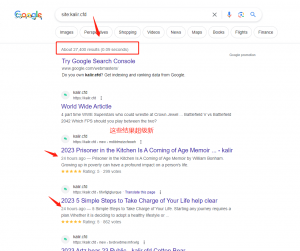
- 我查看了其中一个的索引数据27K,关键字数量也有14K(可怕的是在1天之内增长!上次见过的还是Temu),如图2.3;
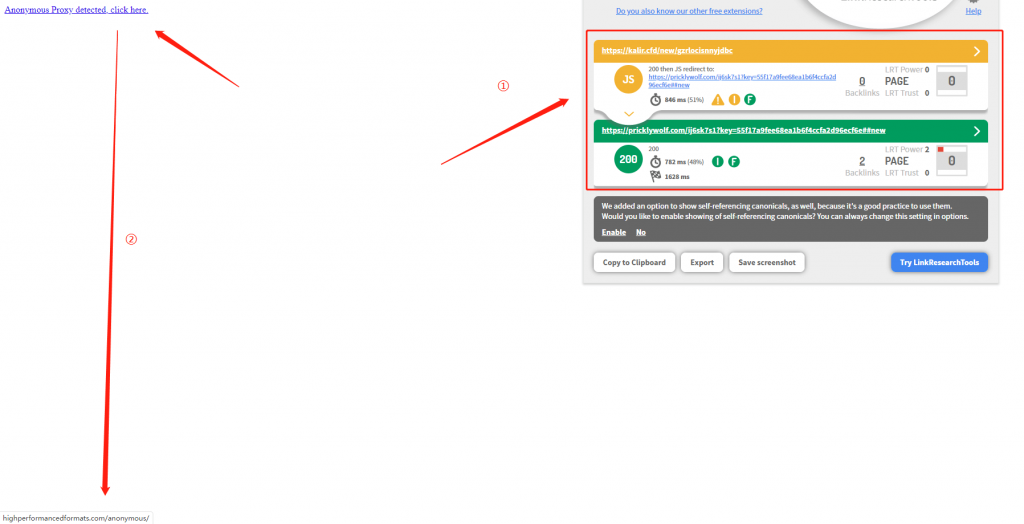
- 首先我采用无痕模式访问了网站(较为安全,避免携带曲奇饼干),马上产生的是一个JS劫持跳转,如图4;
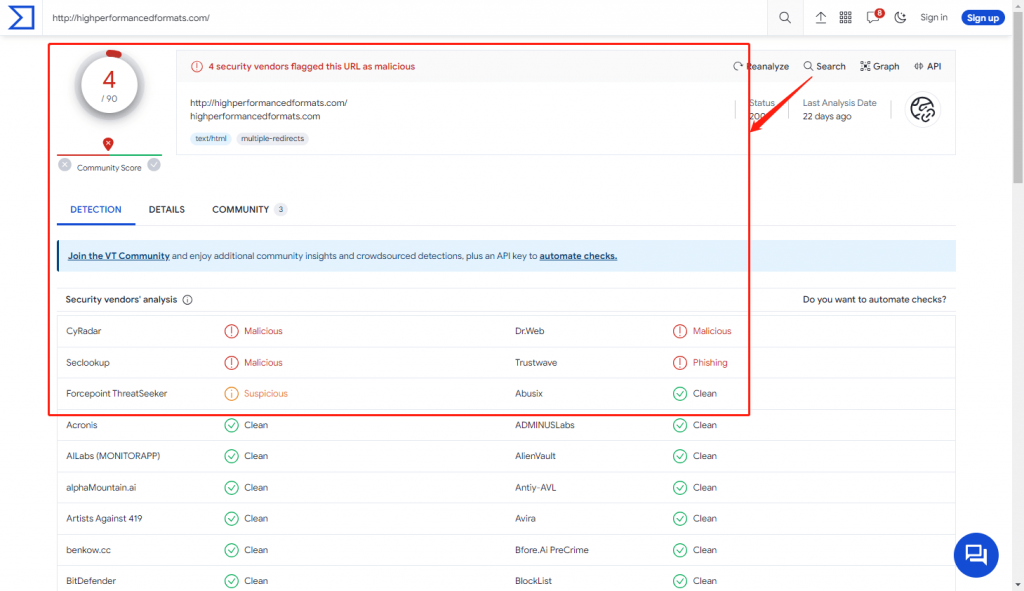
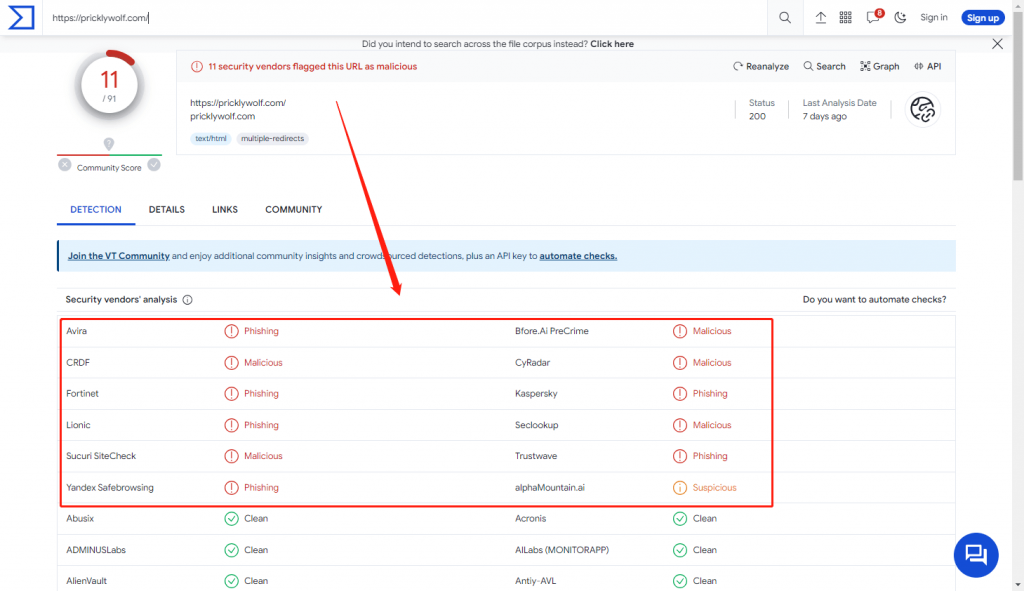
- 这两个网站我都尝试进行病毒检查,结果发现都是嘚物!!!如图5.6;
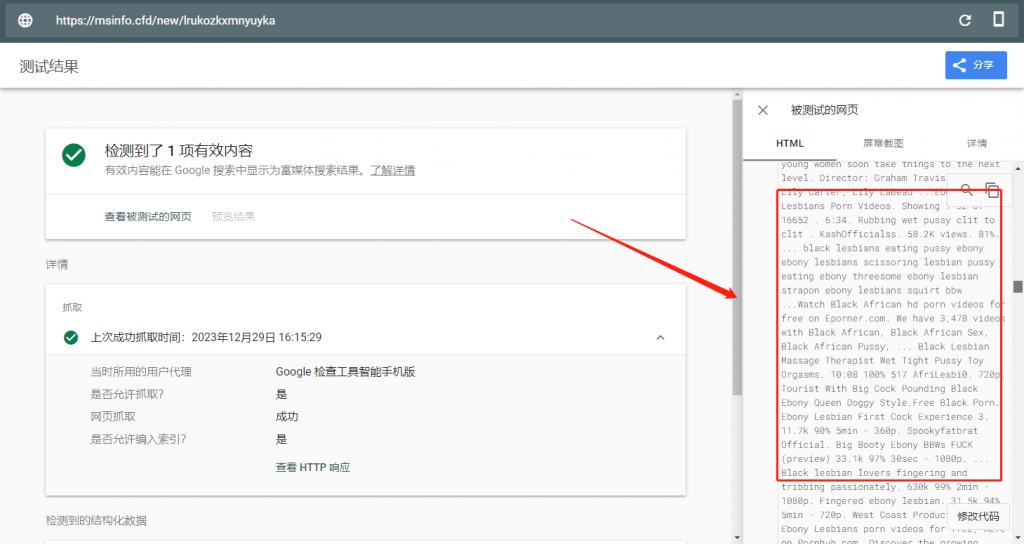
- Googlebot视角都是关键字堆积的内容,如图7;
研究发现:
- 首先确定的是,这部分网站采用了用户代理区分,当识别为机器人的时候,呈现其中一个版本,这个版本都是垃圾内容堆积(关键字),当识别为用户的时候,采用JS跳转至另一个网站,当然,这个网站必须是被劫持(病毒感染),所以用户则无法正常访问,Google目前以bot视角抓取渲染这部分页面则为正常的内容,欺骗了机器,这是典型的黑帽手段;
- 其次,这些页面内容所呈现最新关键字,并以最新速度更新在搜索结果中!我检查了页面的标题与摘要,标题和摘要为空模板,而这些Hacker抓住了Google会依据用户搜索关键字和网页内容重写的规则,留空了这两个标签,所以原页面在已经一定的相关性搜索词,例如我搜索的是i15pro max,原有的页面没有这个关键字,但是有许多iPhone,i14等这类相关关键字,Google系统识别这是相关的,重写了标题的摘要;
- 这类网站目前都为porn类词排名,在搜索上,porn和casino都是主要的大流量来源,Hacker可以先通过获取这部分词进行内容创建,并堆积其他的关键字,从而Ping爬虫对这个页面进行爬取,所以一定情况下,它可以利用Googlebot爬取机制,识别这个页面的更新频率,并请求重新索引页面,最后出现在搜索结果中。要知道,对于新网站,Google无法第一时间评估其内容质量,后续会根据用户交互数据对排名进行细化;
- 今年第四季度Google出现了非常多的更新,而许多用户也发现了SERPs中出现了许多垃圾内容,毕竟机器无法百分百完美,而Google也已经开始在处理该问题,毕竟搜索主要是为用户呈现高质量且有价值,帮助的内容,这往往需要些时间,但是目前黑帽的SEOer还是在不断钻排名系统的漏洞,这肯定是不长久的,最多也是短暂的愉悦,但是这种技术确实很厉害,可以了解但是不推荐。
*精简要点:
- SERPs依旧充斥着许多垃圾内容;
- Google无法百分百识别哪些内容好,哪些坏;
- Google依靠SERP上的用户交互来评估内容质量;
- 对于新网站,Google无法第一时间评估其内容质量,后续会根据用户交互数据对排名进行细化;